久々に東京ドームに長男一家と親戚の子供と一緒に行った。巨人―DeNA戦。 2人とも少年野球、高校野球の選手とあって開始前2時間に集合して練習風景からの観戦。二人は硬球のバッティング音にさすがプロは違うなぁと感想。だが、試合が始まると野球というより応援、チアガールなどショウー的な割合が多くなり、プロの技術を味合うにはほど遠い状態。ピリッとしない先発投手。カッコイイ捕球とスローイングを見せるべくしてエラーを重ねる巨人。つられて押し出し連発の2級投手陣。老害解説者の走り込み不足発言に日頃は眉を顰めていた小生でも「キャンプ不足ではないのか?」と言いたくなった試合内容。眠っていたDeNAの主砲を目覚めさせて、今後のペナントレースを面白くするに貢献した試合と理解して7回終了したところで球場を後にした。
プロ野球のスキルを見たいならM L Bに限る。筆者の長男がまだ小学校の頃、ML Bを観戦に行った。野茂が登場する日だった。入場するときにスタッフから呼び止められて、なんのことか分からずにいたら、なんと「始球式」に。その時の感激は今も残っている。
それにしても観戦中のスナック・アルコールの類は昔より少なくなった感はあるが、いかにも健康に良いとは言えないものが多い特徴は今も変わらない。話は転じて食事と高血圧について面白いコホート研究報告がある。この類の情報はyou tubeで過剰に出てくるのでいつものことなのかと文献を眺めていた。結果は至極真っ当で誰でもわかる。だが、その結果に持ってくるには機械学習処理を駆使している。そこに文献を読む意味があると気がついた。 要旨を引用する(下線部が引用部分 文献タイトル:高血圧発症と関連する日本人成人男性の食事パターン:コホート研究への機械学習の適用 東北大学)
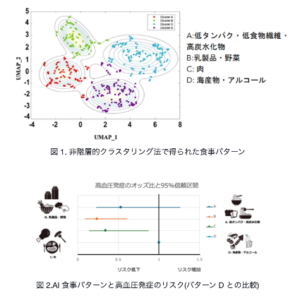
協同組合仙台卸商センター組合員男性 447 名を 2008 年から 2010 年まで 2年間追跡したコホート研究データから AI による食事パターンの分類を試み、高血圧発症リスクとの関連を検討しました。BDHQ に含まれる 58 の食品の一週間の摂取頻度、12 の食行動、9 つの調理方法のデータを次元削減(注 5)・可視化法の一つである UMAP(Uniform Manifold Approximation and Projection)で処理したのちに教師なし機械学習(注 6)による非階層的クラスタリング法(注 7)であるk-means 法で分類を行いました。食事パターンはそれぞれの摂取頻度の高い食品から「海産物とアルコール飲料」「低タンパク・低食物繊維・高炭水化物」「乳製品・野菜」「肉」の 4 種類に分類されました。2 年間の追跡期間中の高血圧症の発症は、「海産物とアルコール飲料」に比べて「乳製品・野菜」および「肉」パターンは、いずれも高血圧の発症リスク(オッズ比(注 8))が 6 割以上小さくなることがわかりました。
いかがでしたか? UMAPとは? そのアルゴリズムは? トポロジカルとは? 多分次から次へ調べる必要がある。そして、その結果は複雑系を整理することが次世代技術開発の肝であり、時代に取り残されないよう勉強する必要があると痛感した。
勉強しないでいると、2級技術者扱いにされそう。長い期間何をやっていたのか?と呆れられ、誰も見てくれない時代に来た。野球と同じだ。最後に文献の結論図をご参考までに。アルコールを摂りながら贔屓の球団が負けると高血圧になることは間違いがなさそうだ。